
JS의 세계산책
기록유산과 AI (2) - AI가 주는 허위정보, 할루시네이션 본문
ChatGPT와 같은 대규모 언어 모델(LLM)의 성장은 자연어 처리 분야에 전례 없는 혁명적 변화를 일으켰다. 그러나 이러한 모델들이 직면한 큰 도전과제 중 하나는 할루시네이션(hallucination)이라 불리는 부정확하거나 완전히 조작된, AI가 생성한 정보이다. 이 현상 때문에 AI에 대한 신뢰성에 항상 의문이 남으며, 특히 의학정보나 과학연구와 같이 높은 정확도를 요구하는 정보에 대한 지식 접근과 적용을 제한시킨다.
할루시네이션은 LLM이 데이터베이스나 검색 엔진이 아니기 때문에 발생하는 것이다. 사용자가 제시하는 프롬프트를 기반으로 텍스트를 생성하는 원리 속에서 결과는 특정 학습 데이터에 기반하지 않는데서 발생할 수 있는 문제인 것이다. 대표적인 문제는 다음과 같다.
1) 문장 모순: 모델이 같은 응답이나 이전 응답에서 제시한 설명과 정면으로 모순되는 설명을 생성
2) 프롬프트 모순: 출력output이 프롬프트에서 제공한 지침의 정보와 모순
3) 사실 모순: 사실 자체가 부정확하거나 잘못 표현된 콘텐츠를 생성
4) 무작위 LLM 할루시네이션: 예측 불가능하고, 근거가 없으며, 일관성이 무너진 설명을 생성
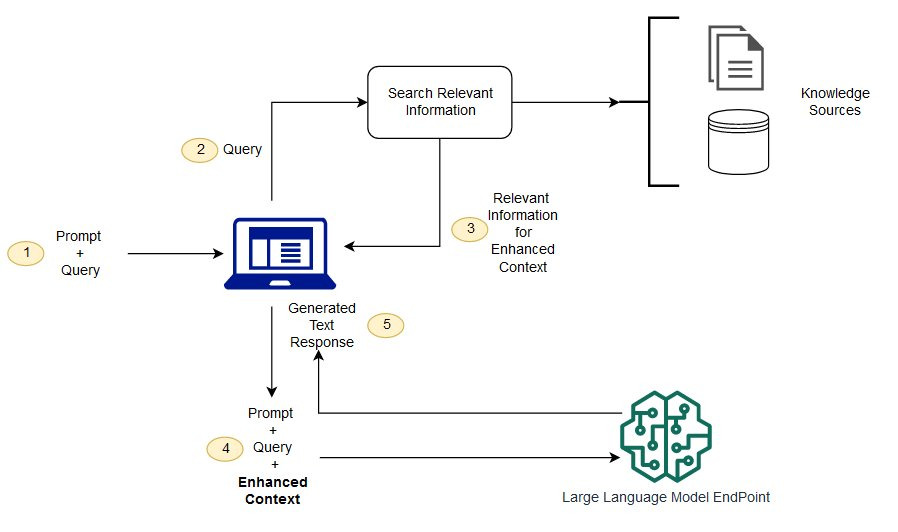
위 문제를 해결하기 위해서 적용되는 프로세스는 검색증강생성(Retrieval-Augmented Generation, RAG)이다. RAG를 LLM에 적용시켜 최신의 정보를 정확한 응답으로 제공하는 것으로 모델의 기능을 향상시키는 방법이다. RAG 지원 프롬프트를 통해 LLM의 출력이 최신 사항을 반영하도록 설계되는 것이다. 이를 통해 최신 정보를 제공하여 사용자의 요구에 부합하는 관련성을 높이면서도, 해당 정보가 인용 또는 참조를 포함시켜 정보의 신뢰성을 강화한다.
'기록유산' 카테고리의 다른 글
| 기록유산과 AI (1) - 기록과 AI (4) | 2024.12.19 |
|---|